一、CASE的两种用法
1.1 等值判断->相当于switch case
(1)具体用法模板:
CASE expression
WHEN value1 THEN returnvalue1
WHEN value2 THEN returnvalue2
WHEN value3 THEN returnvalue3
ELSE defaultreturnvalue
END
(2)具体使用示例:
假设我们有一个论坛网站,其中有一张User表{ UId,Name,Level },Level是一个int类型,代表了用户等级类型,例如:1代表骨灰,2代表大虾等;我们就可以用CASE来对其进行等值判断了:
select Name,Rank=( case Level when 1 then '骨灰' when 2 then '大虾' when 3 then '菜鸟' end) from User
1.2 条件判断->相当于if else if else
(1)具体用法模板:
CASE
WHEN condition1 THEN returnvalue1
WHEN condition2 THEN returnvalue2
WHEN condition3 THEN returnvalue3
ELSE defaultreturnvalue
END
注意:then后面返回的数据类型要一致, returnvalue1、 returnvalue2、 returnvalue3的数据类型必须一致。
(2)具体使用示例:
假设我们有一张Score成绩表,里面记录有所有同学的成绩,此时我们想要对所有成绩进行一个评级,比如成绩如果>=90那么则评为A级,>=80且<90则评为B级,这里我们怎来写呢?
select studentId,rank=( case when english between 90 and 100 then 'A' when english between 80 and 89 then 'B' when english between 70 and 79 then 'C' when english between 60 and 69 then 'D' when english < 60 then 'E' else '缺考' end)from Score
二、子查询的用法
2.1 子查询初步
就像使用普通的表一样,被当作结果集的查询语句被称为子查询。所有可以使用表的地方几乎都可以使用子查询来代替。例如:我们如果要找到所有计科一班的同学信息,可以首先通过T_Class表找到计科一班的Id,然后再在T_Student表中找到所有ClassId为计科一班Id的行即可。
select * from T_Student where ClassId=( select Id from T_Class where Name='计科一班')
2.2 单值子查询
只有返回且仅返回一行、一列数据的子查询才能当成单值子查询。例如我们上面提到的例子,子查询中只返回了一个ClassId,这就是单值子查询。当子查询跟随在=、!=、<、<=、>、>=,<> 之后,或子查询用作表达式,只能使用单值子查询。
2.3 多值子查询
如果子查询是多行单列的子查询,这样的子查询的结果集其实是一个集合,那么可以使用in关键字代替=号。例如:我们如果想快速地在T_Student表中删除计科一班和计科二班的所有学生记录,我们可以使用in关键字:
delete from T_Student where ClassId in( select Id from T_Class where Name='计科一班' or Name='计科二班')
2.4 Exists—你存在我深深的脑海里
exists是用来判断是否存在的,当exists查询中的查询存在结果时则返回真,否则返回假。not exists则相反。
exists做为where 条件时,是先对where 前的主查询询进行查询,然后用主查询的结果一个一个的代入exists的查询进行判断,如果为真则输出当前这一条主查询的结果,否则不输出。
exists后面的查询称为相关子查询,即子查询的查询条件依赖于外层父查询中的某个属性值,其处理过程一般为:先取外层查询中的第一个元组,根据它与内层查询中的相关属性值处理内层查询,若where子句返回true,则将此元组放入结果表中,然后取外层查询中的下一个元组,重复这个过程直到全部检查完毕为止。
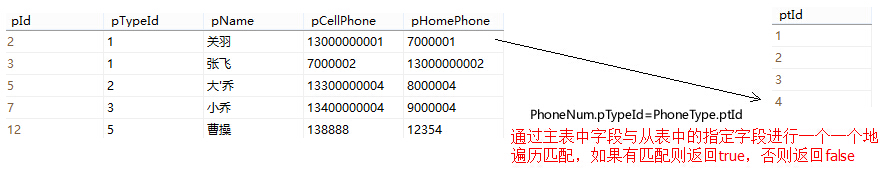
例如:我们有一张人员信息表,里边有一个人员类型Id字段(pTypeId),它是一个外键,对应着人员类型表的主键ptId。如果我们有以下的SQL语句,使用Exists关键字则可以有如下的理解:
select * from Employee e where exists (select * from EmployeeType et where e.pTypeId=et.ptId)
那么,在这句SQL的执行过程中,我们可以将其理解为一个双重的for循环,外边是主表的循环遍历,然后将其放到一个temp变量中,再进入从表的for循环,并与从表的项进行一个一个的按照匹配规则(这里是e.pTypeId=et.ptId)进行匹配,如果有匹配成功则返回true,并且将这一行记录放到要返回的结果集中,否则返回false。
三、手写分页SQL代码
这里假设每页的页大小为10条记录
3.1 利用Top N进行简单分页
(1)如果我们要获取第一页的数据,也就是前10个:
select top 10 * from Account
(2)现在我们要获取第一页之后的数据,也就是第20个~最后一个:
select * from Account where Id not in (select top 10 Id from Account)
(3)现在我们对第20个~最后一个的数据集中取前10个也就成为第二页的数据了:
select top 10 * from Account where Id not in (select top 10 Id from Account)
(4)将上述代码总结为分页代码,设页大小为pageSize,请求页号为pageIndex:
select top @pageSize * from Account where Id not in (select top ((@pageIndex-1)*@pageSize) Id from Account)
PS:这种分页方式的缺点是如果要取很多页之后的数据,那么就要取出前面很多页的ID,查询开销较大,执行效率也就低下。
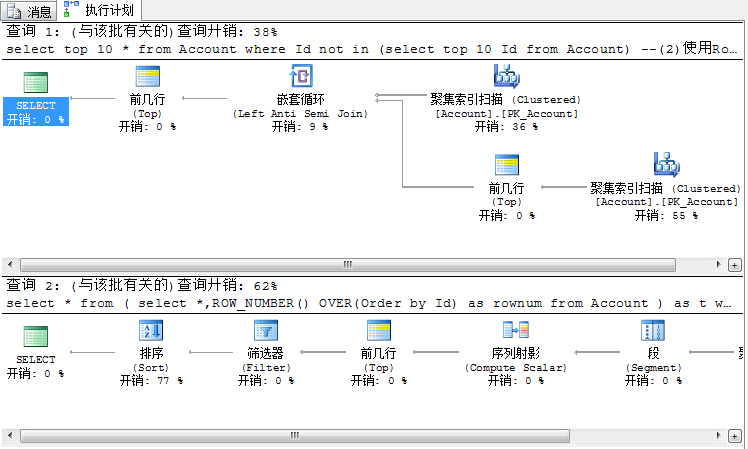
从图中可以看出,在小数据量的对比下,Top N的查询开销较小。但是在大数据量的对比下,Row_Number的方式会取得更高的查询效率以及较小的开销。
3.2 利用Row_Number()进行高效分页
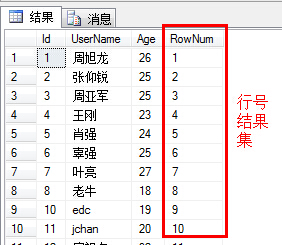
(1)SQL Server 2005后增加了Row_Number函数,可以简化分页代码的实现。首先,Row_Number()是一个排序函数,它可以生成一个有序的行号(如果单靠ID来排序,中间存在断层,例如某一个ID行已经被删除了)。根据MSDN的定义:返回结果集分区内行的序列号,每个分区的第一行从 1 开始。而排序的标准是什么呢?这个就要靠紧跟其后的OVER()语句来定义了。这里我们可以通过一个示例来看看,其生成的行号如何。
select *,ROW_NUMBER() OVER(order by Id) as RowNum from Account
(2)根据ROW_NUMBER()的使用,我们可以将其应用到分页上,于是我们可以写出以下的代码来实现获取第二页的数据集:
select * from ( select *,ROW_NUMBER() OVER(Order by Id) as rownum from Account) as twhere t.rownum between 11 and 20order by t.Id asc
(3)将上述代码总结为分页代码,设页大小为pageSize,请求页号为pageIndex:
select * from ( select *,ROW_NUMBER() OVER(Order by Id) as rownum from Account) as twhere t.rownum between (@pageIndex-1)*pageSize+1 and @pageSize*pageIndexorder by t.Id asc
四、各种连接—JOIN
4.1 Join==Inner Join
默认情况下,使用Join则代表Inner Join内连接,表示两个表根据某种等值规则进行连接。例如下面示例:查询所有学生的学号、姓名及所在班级
select p.Id,p.Name,c.Name from T_Person p join T_Class c on p.ClassId=c.Id
4.2 Left Join
例如:查询所有学生(参加及未参加考试的都算)及成绩,这里涉及到学生表及成绩表,题目要求参加及未参加考试的都要列出来,于是以学生表为基准,对成绩表进行左连接:
select * from Student sleft join SC sc on s.S#=sc.S#
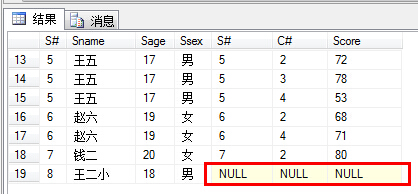
可以通过运行结果图,看到王二小这个童鞋没有参加考试,也就没有成绩。
4.3 Right Join
例如:要查询出所有没有参加考试(在成绩表中不存在的学生)的学生的姓名。于是还是可以以学生表为基准,但是要对成绩表进行右连接:
select * from Student sright join SC sc on s.S#=sc.S#
4.4 Cross Join
此种连接在实际应用中不算常见的,但却是理论基础,因为它代表了笛卡尔积。其实,所有连接方式都会先生成临时笛卡尔积表,笛卡尔积是关系代数里的一个概念,表示第一个表的行数乘以第二个表的行数等于笛卡尔积结果集的大小。
select * from Student scross join SC sc
这里假如Student表中有10行记录,SC表中有20行记录,那么两表进行交叉连接笛卡尔积运算会得到10*20=200行记录的结果集。
五、视图
5.1 三个角度看视图
从用户角度来看,一个视图是从一个特定的角度来查看数据库中的数据。
从数据库系统内部来看,一个视图是由SELECT语句组成的查询定义的虚拟表。
从数据库系统内部来看,视图是由一张或多张表中的数据组成的;从数据库系统外部来看,视图就如同一张表一样,对表能够进行的一般操作都可以应用于视图,例如查询,插入,修改,删除操作等。
5.2 创建视图
例如,我们可以创建一个学生成绩详细信息视图,对一个需要进行三表连接的查询进行封装:
create view vw_scasselect s.S#,s.Sname,c.Cname,sc.Score from Student sjoin SC sc on s.S#=sc.S#join Course c on sc.C#=c.C#
然后,我们对vw_sc进行select查询:
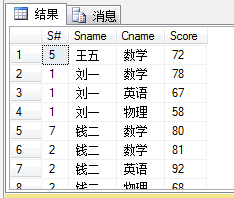
5.3 视图的注意事项
(1)视图在操作上和数据表没有什么区别,但两者的差异是其本质是不同:数据表是实际存储记录的地方,然而视图并不保存任何记录。
(2)相同的数据表,根据不同用户的不同需求,可以创建不同的视图(不同的查询语句)。
作者:
出处:
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。